
TCP Introduction
TCP통신은 신뢰할 수 있는 통신을 위한 연결형 프로토콜이다. TCP통신은 세그먼트가 제대로 전송이 안됐으면 이를 파악해 다시 보내기도하며, 요청이 너무 많으면 전송량을 조절하는 혼잡제어도 수행하며, 처리할 수 있는 만큼의 데이터를 주고 받을 수 있도록 흐름제어도 수행한다.
TCP통신은 프로토콜이기에 데이터가 구성되어져있는 형식이 존재한다. 형식은 아래와 같다. TCP헤더가 총 20byte로 이루어져있고, 나머지는 데이터로 이루어져있다.

TCP프로토콜을 구성하는 Sequence number, Acknowledgement number, control bits, window등에 대해서 알아야한다.
데이터를 한 번에 다 보낼 수 없기때문에 분할해서 보내는데 각각의 요소를 세그먼트라고 부른다. 이 세그먼트에도 순서가 있기때문에 구분을 위해 각 세그먼트마다 Sequence number를 부여한다. 수신 호스트는 세그먼트를 받은 후, 다음에 기대하는 Sequence Number를 Acknowldegement number에 첨부해 전송한다.
아래 dockerfile을 사용해서 http://www.google.com 요청을 보냈을 때 어떤 패킷이 오고가는지 wireshark를 통해 분석해보자.
Wireshark를 통한 packet capture
아래 Dockerfile을 만들어서 아래 명령어로 실행했다.
docker image 빌드 -> docker build -f Dockerfile . -t pcap-test
docker run --name pcap-test pcap-test && docker cp pcap-test:/app/out.pcap ./out.pcap
FROM python:3.10-slim
RUN apt-get update && apt-get install -y \
curl wget net-tools ssh telnet tcpdump && \
rm -rf /var/lib/apt/lists/*
WORKDIR /app
# 엔트리포인트 스크립트 생성
RUN echo '#!/bin/sh' > /entrypoint.sh \
&& echo 'tcpdump -i eth0 -U -w /app/out.pcap -c 10 tcp &' >> /entrypoint.sh \
&& echo 'curl --max-time 5 http://www.google.com' >> /entrypoint.sh \
&& echo 'wait' >> /entrypoint.sh \
&& chmod +x /entrypoint.sh
CMD ["/entrypoint.sh"]

1~3번째 packet은 아래에서 나오는 연결수립을 위한 three-way handshake이다.

Seqence number, Ack number window, MSS등 여러 값들을 볼 수 있다. GET / HTTP/1.1 요청이 Length가 78이었기때문에 다음 패킷에서 Ack는 1 + 78해서 79이고, 확인했다는 응답을 보낸 후, 데이터를 전송하는데 이때 Len이 2800이므로 호스트가 잘 받았다고 보내는 세그먼트는 1 + 2800 해서 2801을 담아서 보낸다.
TCP 연결 수립과 종료
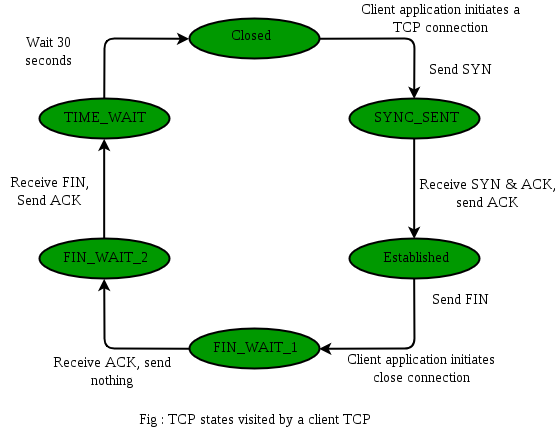
연결 수립: Three-way handshake
TCP연결은 클라이언트가 SYN 세그먼트를 전송하고, 서버가 SYN + ACK 세그먼트를 전송한 뒤, 다시 클라이언트가 ACK 세그먼트를 전송하는 3단계로 이루어진다. 이 과정은 서버와 호스트가 Sequence number와 Acknowledgement number를 맞추는 과정이다.
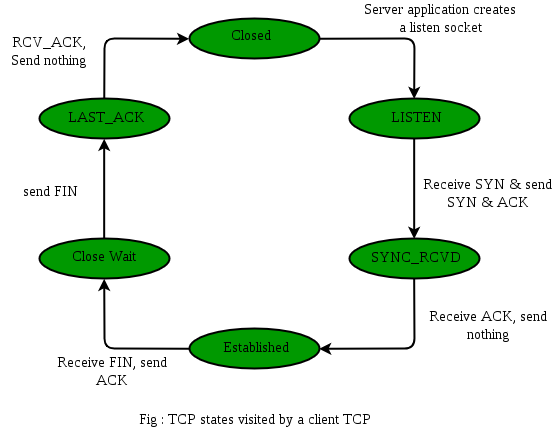
연결 종료
연결종료는 연결수립에서 한 단계가 더 추가되었다. 클라이언트가 연결을 끝낸다는 패킷을 보냈다고 서버에서 바로 끝내버리면 될까? 아니다! 아직 진행중인 프로세스가 있을수 있기때문에 이것들이 다 종료되면 그 때 종료해야한다.
따라서, Client가 종료하겠다는 FIN 세그먼트를 전송하면 서버는 잘 받았다는 ACK를 전송하고, 종료할 준비가 되면 그때 FIN 세그먼트를 클라이언트에게 전송한다. 그러면 클라이언트가 잘 받았다고 ACK를 전송하면 연결이 종료된다.
아래 그림에서 왼쪽을 보면 CLOSE WAIT 상태가 있다. 이는 FIN 세그먼트를 보내기 전에 상태이다.
TCP의 핵심기능1 : 오류제어
데이터 전송에서 문제가 생겼음을 판단하는 방법
TCP헤더에 체크섬필드가 있어 데이터가 손상되었음은 파악할 수는 있지만, 데이터가 제대로 전달되지 않았음을 송신호스트가 인지할 수는 없다. 그래서 재전송은 송신 호스트가 이를 인지하는 것이 핵심이다. 이를 인지할 수 있는 방법은 두 가지가 있다.
1. 중복된 ACK 세그먼트를 수신했을 때
[1], [2], [3]의 패킷을 전송했는데 수신 호스트가 [2]를 받지못했으면 [2]를 보내달라고 송신 호스트에게 전송한다. 이를 3번 받으면 뭔가 잘못되었음을 인지하고 다시 데이터를 전송한다. 이를 Fast Retransmit이라고한다.
2. 타임아웃이 발생했을 때
OS는 TCP통신을 할 때 메시지를 전송한 뒤 그에 대한 답변을 받는 데까지 걸리는 시간인 RTT(Round Trip Time)을 동적으로 계속 계산한다. 그리고 이 시간이 초과되면 문제가 있다고 판단해 다시 보낸다. RTT는 마냥 기다리는 방식이어서 시간지연이 발생해 1번을 더 많이 사용한다.
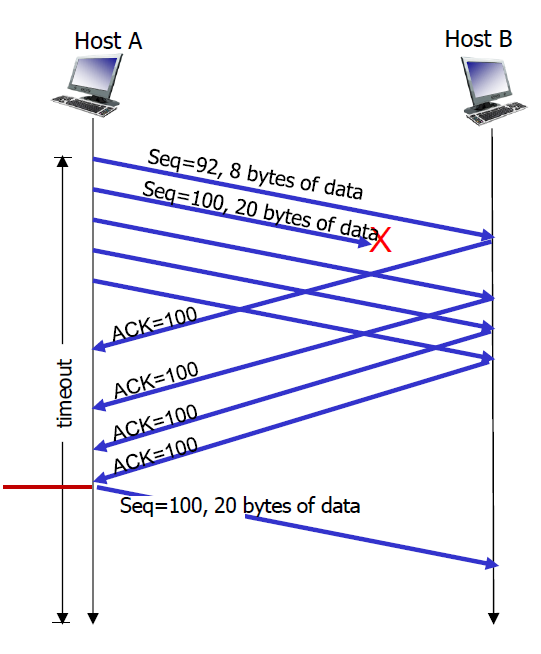
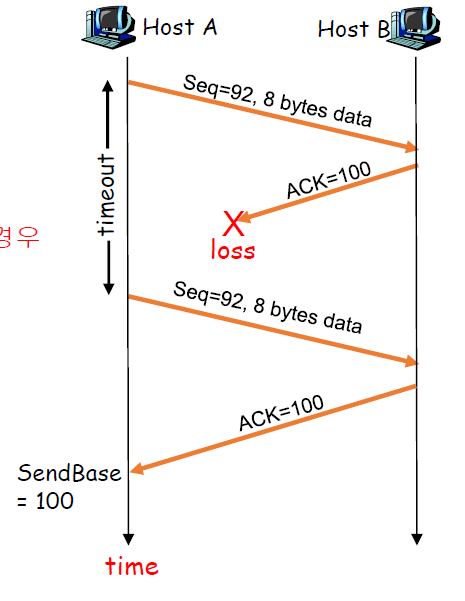
TCP Retransmission scenarios
왼쪽 사진은 ACK 세그먼트가 전송이 안되서 timeout이 발생했고, 재전송하는 시나리오.
중간 사진은 도착은 했지만, timeout이후에 도착해 재전송되는 시나리오
오른쪽 사진은 ACK 100은 도착하지 않았지만, Timeout전에 ACK 120이 도착해서 그 전의 세그먼트도 잘 도착했구나라고 판단하는 시나리오(재전송 X) -> TCP는 Cumulative ACK이라는 점!


데이터를 다시 보내는 방법
Stop-and-Wait ARQ
데이터를 보낸 후에 ACK 세그먼트를 받기까지 보내지 않는 방식이다. 안정성은 높지만 속도가 느리다.
Go-Back-N ARQ
데이터를 계속 보내다가 잘못 전송된 데이터가 있으면 그 데이터 이후로 전부 다시 보내는 방식이다.
Seletive Repeat ARQ
데이터를 계속 보내다가 잘못 전송된 데이터가 있으면 그 데이터만 다시 보내는 방식이다. 수신측에서는 어떤 데이터를 받았고, 못받았는지를 기억해야하기때문에 버퍼가 필요하다.
TCP의 핵심기능2 : 흐름 제어
TCP의 흐름 제어는 수신 호스트의 처리 속도에 맞추어 송신 속도를 조절함으로써 수신 버퍼의 오버플로우를 방지하는 기능이다.
이를 위해 수신 측은 자신의 여유 버퍼 크기(윈도우 크기)를 TCP 헤더의 window 필드에 담아 송신 측에 전달하며, 송신 측은 이 값을 기반으로 한 번에 전송할 수 있는 데이터 양을 결정한다
TCP의 핵심기능3 : 혼잡 제어
혼잡제어를 하지 않으면 해당 데이터를 보내고 ACK 세그먼트를 받기까지의 시간이 오래걸린다. 그러면 송신호스트는 뭔가 잘못된거라 판단하고 재전송을 하고, 그러면 버퍼에 더 많은 데이터가 쌓여 인터넷이 붕괴된다. 따라서 혼잡 제어는 엄청나게 중요한 기술!
흐름제어의 주체가 수신 호스트라면, 혼잡 제어의 주체는 송신 호스트이다. 흐름제어에서 사용되는 윈도우의 크기는 수신 호스트로부터 받는 값이지만, 혼잡 제어에서는 얼마나 혼잡한지를 라우터가 알려주지않기에 호스트가 대충 때려맞춰서 얼마나 보내야할 지 계산해야한다. 얼마나 보낼지에 대한 정보가 혼잡 윈도우이며, 이걸 계산하는데 사용하는 가장 기본적인 알고리즘이 AIMD(Additive Increase/Multiplicative Decrease)이다. 이 알고리즘은 간단한다. loss가 없을 때까지 선형적으로 전송율을 올리다가 loss가 감지되면 확 줄여버린다.
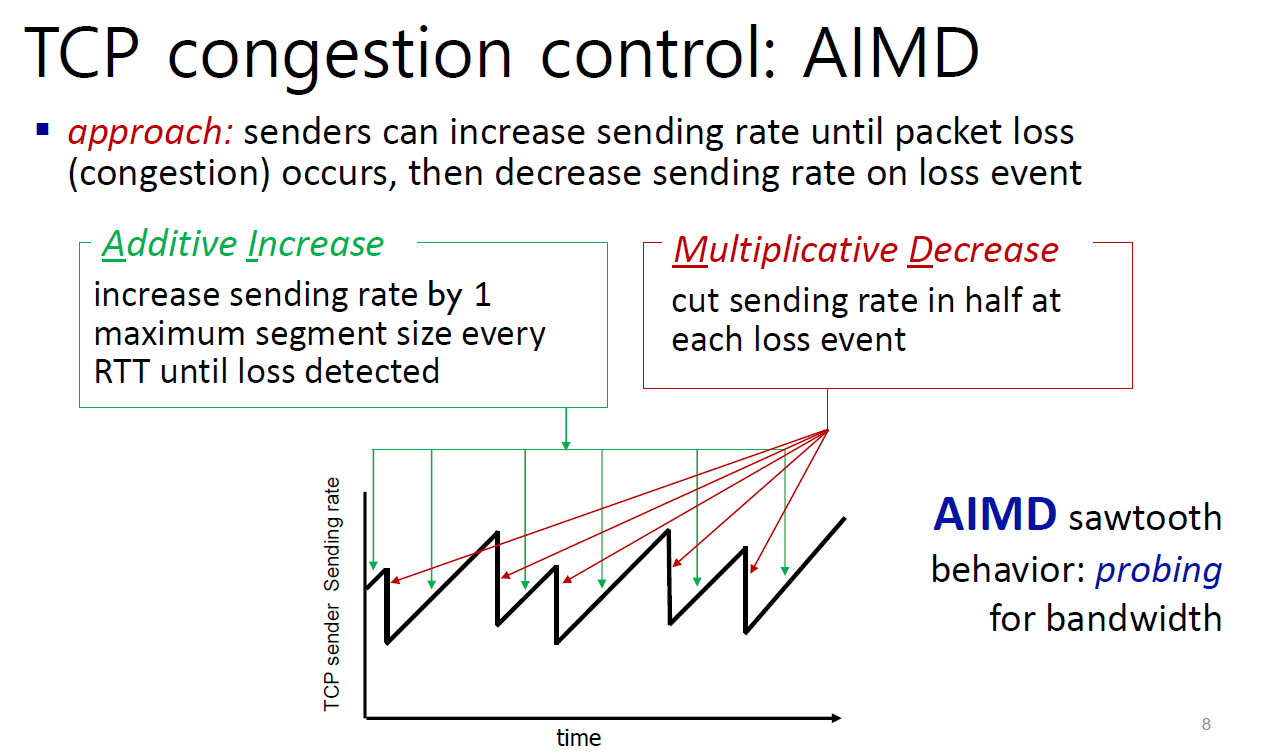

TCP의 주요버전으로는 TCP Tahoe, Reno, New Reno, Cubic이 있다.
cwnd (congestion window) : 송신자가 네트워크 상태를 추정하여 조절하는 윈도우
awnd (advertised window) : 수신자의 윈도우 크기(TCP헤더에 포함)
slow start : 네트워크 상황을 모르기때문에 cwnd를 지수적으로 증가시키는 방식(원래는 1부터 시작했지만, 최근에는 10부터 시작)
ssthresh : slow start 구간에서 congestion avoidance구간을 결정하는 값
congestion avoidance : cwnd를 선형적으로 증가시키는 방식
MSS(Maximum Segment Size) : TCP 세그먼트에서 Payload(순수 데이터)로 담을 수 있는 최대 바이트 수 (보통 1500 byte인데 TCP 헤더, IP헤더 빼면 1460byte)

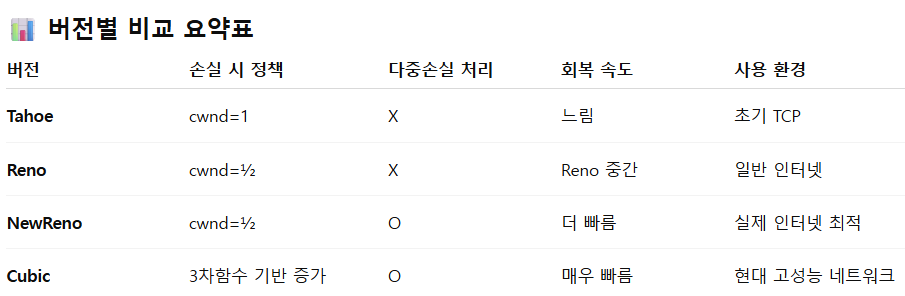
TCP 혼잡 제어 알고리즘 버전별 정리
TCP Tahoe
- 손실 감지 방식
- 타임아웃 → 손실 감지
- 중복 ACK 3개 → Fast Retransmit 지원
- 손실 대응 정책
- cwnd = 1로 초기화 (Slow Start로 돌아감)
- 특징
- 보수적 → 회복 속도가 느림
TCP Reno
- Tahoe 개선 버전
- 손실 감지 방식
- 중복 ACK 3개 → Fast Retransmit
- 손실 시 Fast Recovery 모드 진입
- Fast recovery모드에서는 Slow start로 돌아가지않고 Congestion Avoidance구간에서 cwnd값이 증가한다. 또한, Fastretransmit이 발생했다는 것은 ACK를 세 번 수신했다는 뜻이기에 cwnd = ssthresh + (3*MSS)부터 시작한다.
- 손실 대응 정책
- cwnd = cwnd / 2 (Multiplicative Decrease)
- ssthresh = cwnd / 2 로 업데이트
- 특징
- 회복 속도 개선
- 단점: 다중 패킷 손실 발생 시 성능 매우 저하
TCP NewReno
- Reno의 다중 손실 처리 개선
- Fast Recovery 상태에서도
여러 손실 패킷을 한 번에 복구 가능 - 특징
- 혼잡 상황에서 더 안정적인 Throughput 유지
- Reno 대비 실제 인터넷 환경에서 성능 크게 향상
TCP Cubic (Linux Default)
- 고속 네트워크(대역폭↑, 지연↑) 환경 최적화
- 윈도우 증가 정책
- Congestion Avoidance 구간에서 선형 증가(X) → 3차 함수 기반 윈도우 확장
- RTT 영향 ↓
- 특징
- 대규모 데이터 전송에 최적
- 빠른 회복 + 높은 링크 활용도
TCP BBR
Multipath TCP
UDP
UDP는 TCP와 달리 비연결형 통신을 수행하는 신뢰할 수 없는 프로토콜이다. UDP는 TCP에 비해 적은 오버헤드로 패킷을 빠르게 처리할 수 있다. 그래서 주로, 실시간 스트리밍 서비스, 인터넷 전화처럼 실시간성이 강조되는 상황에서 TCP보다 더 많이 쓰인다.

'Robot > Computer Network' 카테고리의 다른 글
| [Computer Network] HTTP/TLS/HTTPS (1) | 2025.10.18 |
|---|